What is a container loop?
A container loop is a state of a container execution that can not stabilize itself and therefor restarts infinitely. This can be caused by multiple reasons.
Receiving loop notifications
During the setup of new container cluster we ask for an optional emailaddress to which we should automatically forward loop notifications. In case you don’t receive them but you want to apply for the process please contact our service team and provide them your desired emailaddress.
Additional to the automatic process our service team also informs you about container loops after a first analysis from our end.
Dealing with loops
There are serveral causes for loops. Not all loops equal a downtime of your application but you should deal with all types of loops immediatly as they might cause more severe problems if they persist for to long.
Identifying loop issues
As soon as you have received a notification from us you should look into the following.
Container Event Logs
r3 container show --events --container-type your_container
Will show you the events of the specific service:
[
{
"events": [
{
"id": "5ae3ecde-52e1-4072-bdb1-cd0ce5ebb65e",
"createdAt": "2021-07-21T10:05:26.019000+00:00",
"message": "(service testempty-empty-test-blue) has reached a steady state."
},
{
"id": "0f589e68-a736-4235-88b8-078ff4ccb181",
"createdAt": "2021-07-21T10:05:26.018000+00:00",
"message": "(service testempty-empty-test-blue) (deployment ecs-svc/3420576820905894298) deployment completed."
},
{
"id": "80c1be4c-e488-4f8d-ad34-924be77201cb",
"createdAt": "2021-07-21T10:04:12.676000+00:00",
"message": "(service testempty-empty-test-blue) has stopped 1 running tasks: (task c9dc8605644f48c6a2ca06b525afde9a)."
},
{
"id": "a04c304c-1ce8-49ed-a15e-e6746240f685",
"createdAt": "2021-07-21T10:03:08.694000+00:00",
"message": "(service testempty-empty-test-blue) has started 1 tasks: (task 221b7f1e056d46f587dbf37abe2d2ae8)."
},
{
"id": "f0f58ebe-b490-46d0-bf07-7b7ba5fecb17",
"createdAt": "2021-07-21T09:46:16.555000+00:00",
"message": "(service testempty-empty-test-blue) has reached a steady state."
}
]
}
]
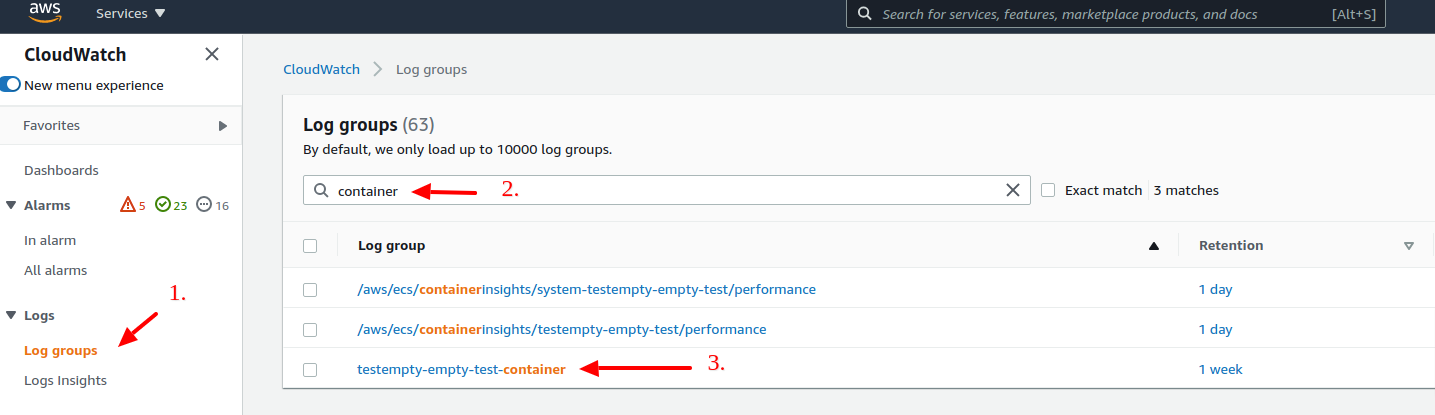
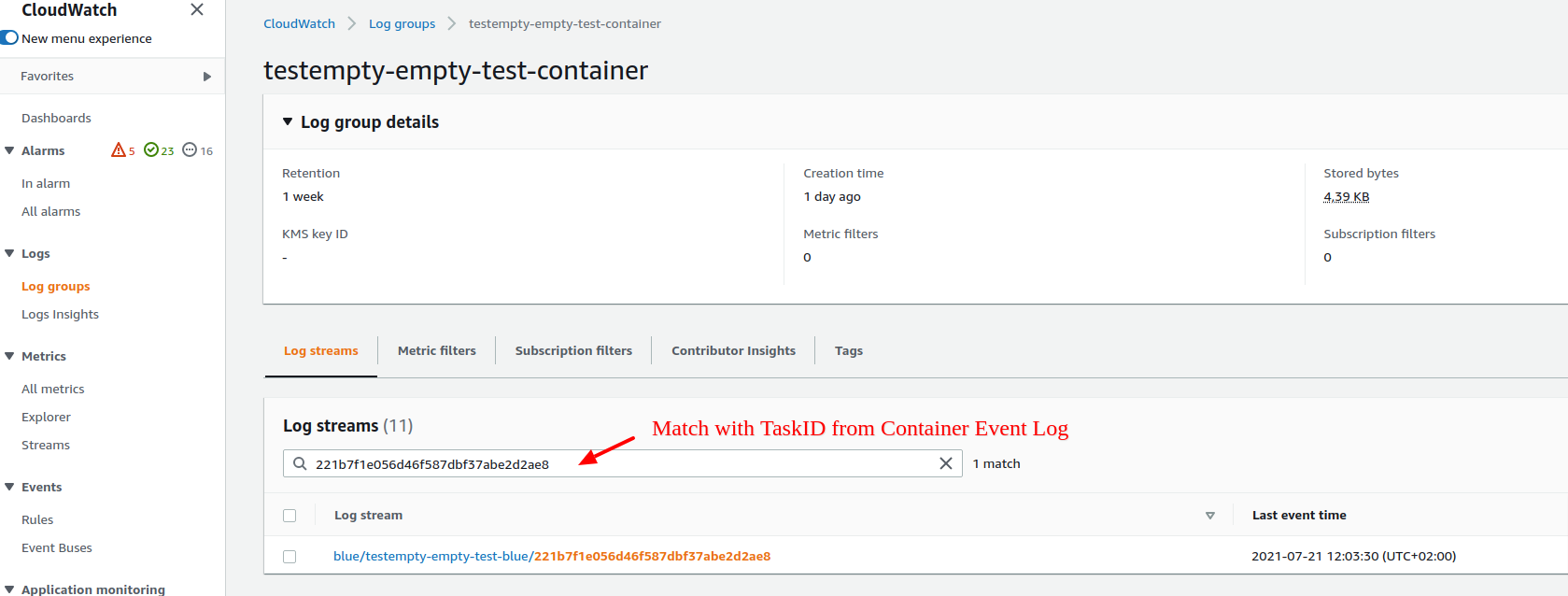
Container Logs
By default your container logs are send to Cloudwatch for which you received an user during the initial setup of your environment. With that user you can log into AWS console and navigate to the service Cloudwatch.
Types of loops
Broken container image
In this case a container image was deployed that itself wasn’t able to run. A common issue is that the application tries to execute a command during the container startup and that command fails. Therefor the PID 1 of your container terminates/restarts. As soon as this happens ECS detects the issue and kills the current container execution. If the issue persists ECS will recreate the container infinitely.
Event Log Message
Container start without further message regarding state
{
"id": "69d87d89-1d63-4cff-9746-6f6dc137eb29",
"createdAt": "2021-07-22T13:15:28.796000+00:00",
"message": "(service testempty-empty-test-blue2) has started 1 tasks: (task bf7b80ed0c6e49c1b973fdff7642ac27)."
},
{
"id": "155d438a-9377-4cbd-aacf-9aa5aa16f3c3",
"createdAt": "2021-07-22T13:13:17.848000+00:00",
"message": "(service testempty-empty-test-blue2) has started 1 tasks: (task f4a07925789b4bbea41160a976b846a7)."
},
{
"id": "158d5f8d-37d8-4de6-84ae-68bd3ae8634c",
"createdAt": "2021-07-22T13:12:13.035000+00:00",
"message": "(service testempty-empty-test-blue2) has started 1 tasks: (task d99cd6ec10e244b2b49ed9977c684c11)."
},
{
"id": "cd368cbf-807a-4097-a0bf-ca8c692410a3",
"createdAt": "2021-07-22T13:11:10.434000+00:00",
"message": "(service testempty-empty-test-blue2) has started 1 tasks: (task 633684559bb64b4daaf256f4e139b843)."
}
Solution
Identify what is causing your container image to fail by checking your container logs and deploy a working image afterwards.
Container image not available
It is possible to delete a container image from your registry while the container is still running with that image. In case your desired image is deleted while you have container autoscaling enabled ECS might try to start a container due to higher load with an image that no longer exists. This will not break your already running containers but new container will loop as they can not be started successful.
Event Log Message
Container start without further message regarding state
{
"id": "69d87d89-1d63-4cff-9746-6f6dc137eb29",
"createdAt": "2021-07-22T13:15:28.796000+00:00",
"message": "(service testempty-empty-test-blue2) has started 1 tasks: (task bf7b80ed0c6e49c1b973fdff7642ac27)."
},
{
"id": "155d438a-9377-4cbd-aacf-9aa5aa16f3c3",
"createdAt": "2021-07-22T13:13:17.848000+00:00",
"message": "(service testempty-empty-test-blue2) has started 1 tasks: (task f4a07925789b4bbea41160a976b846a7)."
},
{
"id": "158d5f8d-37d8-4de6-84ae-68bd3ae8634c",
"createdAt": "2021-07-22T13:12:13.035000+00:00",
"message": "(service testempty-empty-test-blue2) has started 1 tasks: (task d99cd6ec10e244b2b49ed9977c684c11)."
},
{
"id": "cd368cbf-807a-4097-a0bf-ca8c692410a3",
"createdAt": "2021-07-22T13:11:10.434000+00:00",
"message": "(service testempty-empty-test-blue2) has started 1 tasks: (task 633684559bb64b4daaf256f4e139b843)."
}
Solution
Reupload the image to your personal registry or deploy the new image instead.
Failing Healthcheck
If a container is connected to any loadbalancer we perform a mandatory healthcheck. This healthcheck calls a defined path within you container (ie. /health) and expects a predefined return code (by default 200). If the healthcheck returns a different code the container is marked as unhealthy and will be stopped immediatly. ECS will than spawn new containers until the healthcheck is passed.
Event Log Message
Status code is prompted
{
"id": "ac751929-9418-4712-9700-eb39fb603767",
"createdAt": "2021-07-22T09:29:49.733000+00:00",
"message": "(service testempty-empty-test-blue2) (port 80) is unhealthy in (target-group arn:aws:elasticloadbalancing:eu-central-1:878353521853:targetgroup/teste-r3Def-1I0FAKO579F3I/7f0a3f88128acd9d) due to (reason Health checks failed with these codes: [404])."
}
Solution
Check your container logs why it is not giving the intended state code. In case the code/path has changed and needs to be altered please contact our service team.